抽象数据类型是软件工程中一个普遍原则的实例,要解决如何设计良好的抽象数据结构,通过封装来避免使用者获取数据的内部表示
什么是抽象?
从抽象数据类型可以衍生出很多意思相近的名词,这里列出几个能表达其中思想的词:
- 抽象:忽略底层的细节而在更高层思考
- 模块化:将系统分为一个个模块,每个模块可以单独地进行设计、实现、测试、推导,并且在剩下的开发中进行复用
- 封装:在模块外部建立起一道“围墙”,使它只对自己内部的行为负责,并且系统其它地方的代码不会影响到它的内部
- 信息隐藏:将模块的实现细节隐藏,使未来更改模块内部时不必改变外部代码
- 功能分离:一个模块仅仅负责一个特性/功能,而不是将一个特性运用在很多模块或一个模块拥有很多特性
事实上,上一节讲到的规约就要体现了这几个方面:
- 抽象:规约使得使用者只需要弄懂规约并遵守前置条件,而不需要弄懂底层的代码实现
- 模块化:单元测试和规约都帮助将方法模块化
- 封装:方法中的局部变量都是被封装起来的,因为它们仅仅可以在方法内部使用。与此相对的是全局变量和指向可变对象的别名,它们会对封装带来很大损害
- 信息隐藏:规约就是一种信息隐藏,它使得实现者可以自由地更改实现代码
- 功能分离:一个规约应该是逻辑明确的,即它不能有很多特性,而应只需实现一种功能
用户定义类型
在早期的编程语言中,用户只能自己定义方法,而所有的类型都是规定好的(例如整型、布尔型、字符串等等)。
而现代编程语言允许用户自己定义类型对数据进行抽象,这是软件开发中的一个巨大进步。
对数据进行抽象的核心思想就是:类型是通过其对应的操作来区分的
- 一个整型就是你能对它进行加法和乘法的东西
- 一个布尔型就是你能对它进行取反的东西
- 一个字符串就是你能对它进行链接或者取子字符串的东西
在 C语言中,似乎有一个类似的东西叫结构体,这种传统的类型强调关注数据的具体表示。但是抽象类型强调作用于数据上的操作:用户不用管这个类型里面的数据是怎么保存表示的,就好像是程序员不用管编译器是怎么存储整数一样,起作用的只是类型对应的操作
和很多现代语言一样,在 Java 中内置类型和用户定义类型之间的关系很模糊。例如在 java.lang中的类 Integer 和 Boolean 就是内置的——Java 标准中规定它们必须存在,但是它们的定义又是和用户定义类型的方式一样的。另外,Java中还保留不是类和对象的原始类型,例如 int 和 boolean ,用户无法对它们进行继承
例如,抽象数据类型Bool有以下操作:
- true :
Bool - false :
Bool - and :
Bool × Bool → Bool - or :
Bool × Bool → Bool - not :
Bool → Bool
抽象数据类型的特征是其操作
就像我们在提及List类型时,和它是linkedlist类型还是array类型没有关系,我们只关注它能不能满足该类型的规约和操作,例如get()方法和size()方法
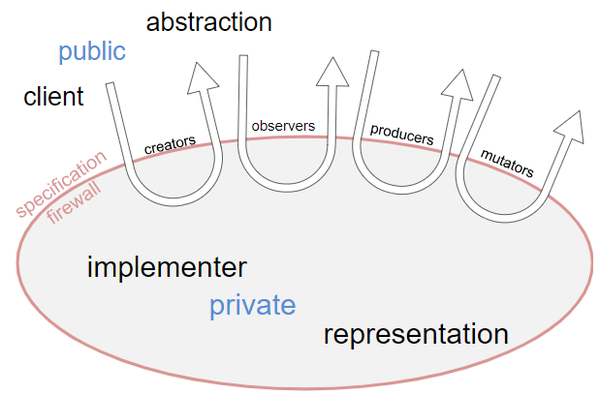
类型和操作的分类
对于类型,不管是内置的还是用户定义的,都可以被分为可改变和不可变两种
其中可改变类型的对象能够被改变:它们提供了改变对象内容的操作,这样的操作执行后可以改变其他对该对象操作的返回值,例如 Date 就是可改变的,因为可以通过调用setMonth操作改变 getMonth 操作的返回值
但 String 就是不可改变的,因为它的操作符都是创建一个新的 String 对象而不是改变现有的这个
有时候一个类型会提供两种形式,一种是可改变的一种是不可改变的,例如 StringBuilder就是一种可改变的字符串类型
抽象类型的操作大致分类:
- 构造器(creator):创建一个该类型的新对象。一个构造器可能会接受一个对象作为参数,但是这个对象的类型不能自己
- 生产器(producer):通过已有的同类型的对象创建新的对象。例如,
String类里面的concat方法就是一个生产器,它接受两个字符串然后据此产生一个新的字符串 - 观察器(observer):接受一个同类型的对象,然后返回一个不同类型的对象/值。例如,
List的size方法,它返回一个int - 变值器(mutator):改变对象的方法,例如
List的add方法,它会在列表中添加一个元素
可以将这些区别用映射来表示:
- creator :
t* → T - producer :
T+, t* → T - observer :
T+, t* → t - mutator :
T+, t* → void | t | T
其中:
T代表抽象类型本身t代表其他的类型+代表这个参数可能出现一次或多次*代表这个参数可能出现零次或多次
例如,String.concat() 这个接受两个参数的生产器的映射为:
- concat :
String × String → String
不接受其它类型参数的观察器List.size():
- size :
List → int
接受很多参数的观察器String.regionMatches:
- regionMatches :
String × boolean × int × String × int × int → boolean
构造器通常都是用构造函数实现的,例如 new ArrayList()
但是有的构造器是静态方法(类方法),例如 Arrays.asList()和 String.valueOf ,这样的静态方法也称为工厂方法
变值器通常没有返回值(void),例如在Java图形库接口中,Component.add() 会将它自己这个对象返回,因此add()可以被连续链式调用
但也不是所有的变值器都没有返回值,例如Set.add() 会返回一个布尔值用来提示这个集合是否被改变了
一些例子
int是Java中的原始整数类型,它是不可变类型,没有变值器
- creators : 值
0,1,2, … - producers : 算术符
+,-,*,/ - observers : 比较符号
==,!=,<,> - mutators : 无
String是Java中的字符串类型,它是不可变类型,故也没有变值器
- creators :
String构造函数,valueOf静态方法(工厂方法) - producers :
concat,substring,toUpperCase - observers :
length,charAt - mutators : 无
List是 Java 中的列表类型,它是可变类型。另外,List也是一个接口,所以对于它的实现可以有很多类,例如 ArrayList 和 LinkedList
- creators :
ArrayList和LinkedList的构造函数,Collections.singletonList - producers :
Collections.unmodifiableList - observers :
size,get - mutators :
add,remove,addAll,Collections.sort
一些抽象数据类型操作分类的例子:
Integer.valueOf() -> creator
BigInteger.mod() -> producer
List.addAll() -> mutator
String.toUpperCase() -> producer
Set.contains() -> observer
Map.keySet() -> observer
BufferedReader.readLine() -> mutator
设计抽象类型的原则
设计一个抽象类型包括选择合适的操作以及它们对应的行为,这里列出了几个重要的规则:
- 设计少量,简单,可以组合实现强大功能的操作而非设计很多复杂的操作
- 每个操作都应该有一个被明确定义的目的,并且应该设计为对不同的数据结构有一致的行为,而不是针对某些特殊情况。例如,不应该为
List类型添加一个sum操作,因为这虽然可能对想要操作一个整数列表的使用者有帮助,但是如果使用者想要操作一个字符串列表呢?或者一个嵌套的列表? 所有这些特殊情况都将会使得sum成为一个难以理解和使用的操作 - 操作集合应该充分地考虑到用户的需求,也就是说,用户可以用这个操作集合做他们可能想做的计算。一个较好的测试方法是检查抽象类型的每个属性是否都能被操作集提取出来。例如,如果没有
get操作,我们就不能提取列表中的元素。抽象类型的基本信息的提取也不应该特别困难,例如,size方法对于List并不是必须的,因为我们可以用get增序遍历整个列表,直到get执行失败,但是这显然就很不方便了 - 抽象类型可以是通用的:例如,列表、集合,或者图。或者它可以是适用于特定领域的:一个街道的地图,一个员工数据库,一个电话簿等等,但是一个抽象类型不能兼有上述二者的特性:要么针对重修按设计,要么针对具体应用设计,而不应该将两者混合,面向具体应用的类型不应包含通用方法;面向通用的类型不应包含面向具体应用的方法
表示独立性(representation independence)
什么是表示独立性?
表示独立:使用者使用 ADT 时无需考虑其内部如何实现,ADT 内部表示的变化不会影响外部的规约和使用者
例如,List就是表示独立的——它的使用与它是用数组还是链表实现的无关。
在实践中,实现表示独立性通常涉及到以下做法:
使用接口和抽象类:定义清晰的接口或抽象类,以此为契约与实现分离。这样,具体的实现可以随时被替换,只要它遵循相同的接口。
限制访问权限:通过合理使用访问修饰符(如private、protected等),限制对类内部数据和方法的访问。
提供访问器(Getter)和修改器(Setter)方法:对于需要外部访问的内部数据,提供访问器和修改器方法,而不是直接暴露类的字段。
例子:字符串的不同表示
下面举一个例子:根据规约自行设计抽象类型的过程,规约如下 > 由于这是一个不可变类型的设计,所以内部如何设计无需告诉外界,所以当两个 MyString 对象事实上指向了同一段 Char 数组地址,仍然可以实现我们的目的,因为是不可变类型
1 | /** MyString represents an immutable sequence of characters. */ |
我们可以简单地用一个字符数组来实现:
1 | private char[] a; |
设计如下操作:
1 | public static MyString valueOf(boolean b) { |
下面的快照图展示了在使用者进行substring操作后的数据状态:
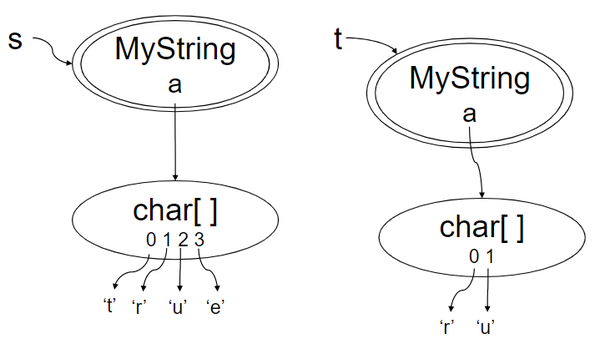
对应代码为:
1 | MyString s = MyString.valueOf(true); |
这种实现有一个性能上的问题,因为这个数据类型是不可变的,那么 substring 实际上没有必要真正去复制子字符串到一个新的数组中。它可以仅仅指向原来的 MyString 字符数组,并且记录当前的起始位置和终止位置
为了优化,我们可以将内部表示改为:
1 | private char[] a; |
通过这种新的表示方法,我们的操作的实现也会发生变化:
1 | public static MyString valueOf(boolean b) { |
刚刚的快照图也就变为了:
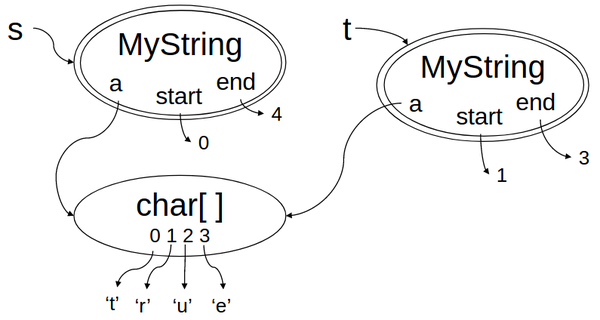
我们改变了操作,提高了性能,而不需要改变其它的代码,这就是表示不变性的力量!
Java 中的抽象数据类型
如下表:
| ADT concept | Ways to do it in Java | Examples |
| Abstract data type | Class | String |
| Interface + class(es) | List and ArrayList | |
| Enum | DayOfWeek | |
| Creator operation | Constructor | ArrayList() |
| Static (factory) method | Collections.singletonList(), Arrays.asList() | |
| Constant | BigInteger.ZERO | |
| Observer operation | Instance method | List.get() |
| Instance method | Collections.max() | |
| Producer operation | Instance method | String.trim() |
| Static method | Collections.unmodifiableList() | |
| Mutator operation | Instance method | List.add() |
| Static method | Collections.copy() | |
| Representation | private fields |
测试抽象数据类型
我们通过测试抽象数据类型中的每一个操作来测试这个抽象数据类型
而这些测试不可避免的要互相交互:我们只能通过观察器来判断其他操作的测试是否成功,而测试观察器的唯一方法是创建对象然后使用观察器

不变量(invariants)
什么是不变量?
不变量是一种属性,它在程序运行的时候总是一种状态,比如不变性(immutability)就是其中的一种:一旦一个不可变类型的对象被创建,它总是代表一个不变的值。当一个ADT能够确保它内部的不变量恒定不变(不受使用者/外部影响),我们就说这个ADT保护/保留自己的不变量
为什么需要不变量?
当一个ADT保护/保留自己的不变量时,对代码的分析会变得更简单,容易发现错误,例如:
- 我们能够依赖字符串(String)的不变性特点,在分析的时候跳过那些关于字符串的代码
- 否则,那么在所有使用(String)的地方,都要检查其是否改变了
不变性——一种不变量
考虑如下不可变类:
1 | /** |
我们应该怎么样做才能确保 Tweet 对象是不可变的(一旦被创建,author, message 和 date 都不能被改变)?
第一个威胁就是使用者可以直接访问Tweet内部的数据,例如:
1 | Tweet t = new Tweet("justinbieber", |
这就是一个表示泄露(representation exposure)的例子,类外部的代码可以直接修改类内部的数据
幸运的是,Java 给我们提供了处理这样的表示泄露的方法:
1 | public class Tweet { |
其中, private 表示只能类内部访问,而final确保了该变量不会被更改,对于不可变的类型来说,就是确保了变量的值不可变
但是这并没有解决全部问题,还是会表示泄露!思考下面这个代码:
1 | /** @return a tweet that retweets t, one hour later*/ |
retweetLater 希望接受一个 Tweet 对象然后修改 Date 后返回一个新的 Tweet 对象。
问题出在哪里呢?其中的 getTimestamp 调用返回一个一样的Date对象,它会被 t.t.timestamp 和 d 同时索引,所以当我们调用 d.setHours()后,t也会受到影响,如下图所示:
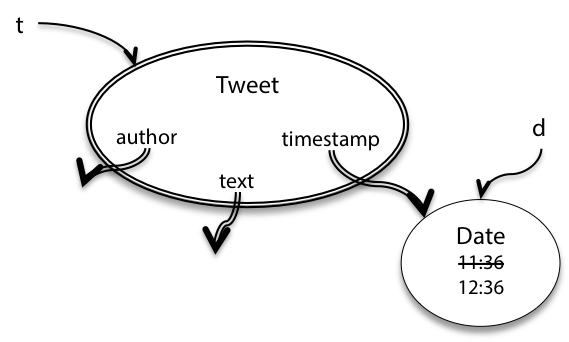
这样,Tweet的不变性就被破坏了,这里的问题就在于Tweet将自己内部对于可变对象的索引泄露了出来,因此整个对象都变成可变的了,使用者在使用时也容易造成隐秘的bug
我们可以通过第 4 章讲到的防御性拷贝来弥补这个问题:在返回的时候复制一个新的对象而不会返回原对象的索引
1 | public Date getTimestamp() { |
可变类型通常都有一个专门用来复制的构造器,可以通过它产生一个一模一样的复制对象
在上面的例子中,Date的复制构造器就接受了一个timestamp值,然后产生了一个新的对象
现在我们已经通过防御性拷贝解决了 getTimestamp返回值的问题,但是还有问题,思考这个代码:
1 | /** @return a list of 24 inspiring tweets, one per hour today */ |
这个代码尝试创建 24 个 Tweet 对象,每一个对象代表一个小时,如下图所示:
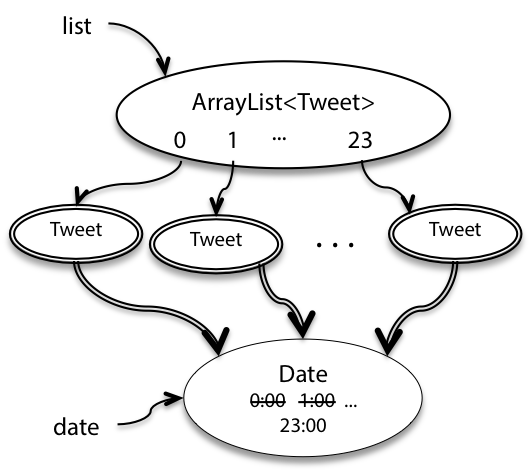
这样,Tweet 的不变性就再次被打破了,因为每一个 Tweet 创建时对 Date 对象的索引都是一样的,所以我们应该对构造器也进行防御性编程:
1 | public Tweet(String author, String text, Date timestamp) { |
通常来说,需要特别注意 ADT 操作中的参数和返回值,如果它们之中有可变类型的对象,就要确保代码没有直接使用索引或者直接返回索引
有同学可能会有疑问,这样不会很浪费吗?毕竟要复制创建这么多新的对象,为什么不直接在规格说明中解决这个问题:
1 | /** |
除非迫不得已,否则不要把希望寄托在使用者上,ADT 有责任保保护自己的不变量,并避免表示泄露
当然,最好的办法就是使用 immutable 的类型,彻底避免表示泄露
表示不变量与抽象函数
表示域与抽象域
在研究之前,先说明两个域:
- 表示域 R:具体的值,是实现者关注的
- 抽象域 A:抽象值,是使用者关注的,例如,一个无限整数对象的抽象域是整个整数域,但是它的实现域可能是一个由原始整数类型(有限)组成的数组实现的,而使用者只关注抽象域
而实现者的责任就是实现表示域到抽象域的映射
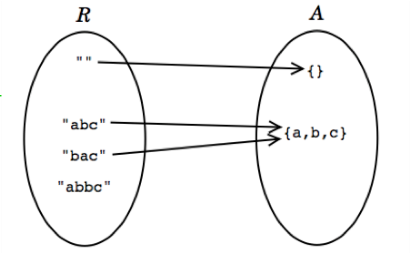
如上图所示,表示域 R 包含的是我们的实现实体(字符串),而抽象域里面是抽象类型表示的字符集合,我们用箭头表示这两个域之间的映射关系。这里要注意几点:
- 抽象值都是满射的,即每一个抽象值都是由表示值映射而来。我们之前说过实现抽象类型的意义在于支持对于抽象值的操作,即我们需要能够创建和管理所有的抽象值,因此它们也必须是可表示的
- 抽象值未必单射,即一些抽象值是被多个表示值映射而来的。这是因为表示方法并不是固定的,我们可以灵活的表示一个抽象值
- 两者未必双射,即不是所有的表示值都能映射到抽象域中。在上面这个例子中,
"abbc"就没有被映射。因为我们已经确定了表示值的字符串中不能含有重复的字符——这样我们的remove方法就能在遇到第一个对应字符的时候停止,因为我们知道没有重复的字符
抽象函数
有了上面的概念,抽象函数就好说了,它是 R 和 A 之间映射关系的函数,即如何将 R 中的每一个值解释为 A 中的每一个值,即如下映射
\[ AF: R \rightarrow A \]
而表示不变量是一个从表示值到布尔值的映射
\[ RI: R \rightarrow boolean \]
对于表示值 r,当且仅当 r 被 AF 映射到了 A 时,RI(r) 为真,也就是说,RI 告诉了我们哪些表示值能够去表示 A 中的抽象值,在下图中,绿色表示的就是 RI(r) 为真的部分,AF 只在这个子集上有定义
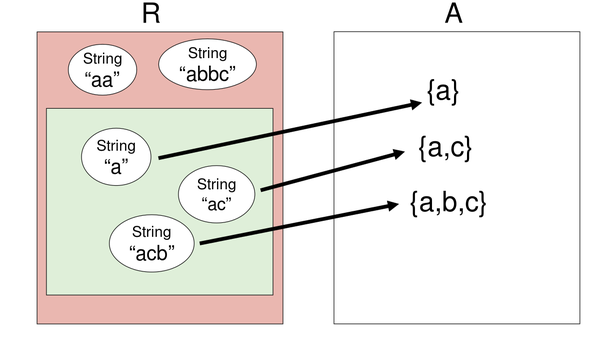
表示不变量和抽象函数都应该在表示声明后注释出来:
1 | public class CharSet { |
即使是同样的 R,同样的 RI,也可能有不用的 AF,即解释不同。比如,同样对于上面的CharSet,如下的解释:
1 | public class CharSet { |
则得到映射为:
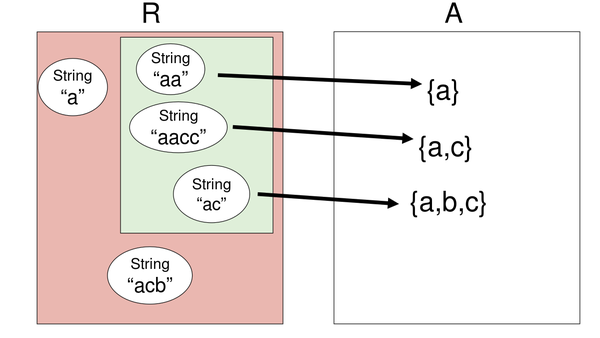
举例:有理数
为了对表示域和抽象域有更深刻的理解,我们可以再举有理数RatNum表示的例子
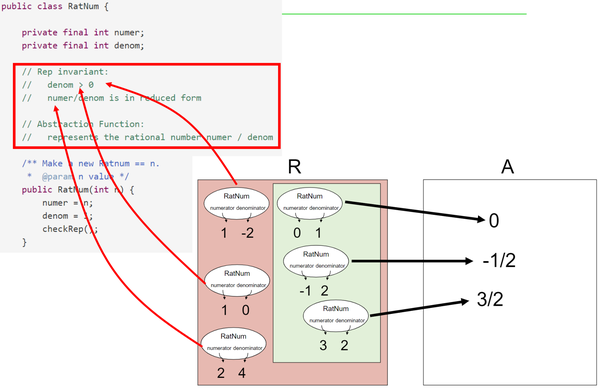
代码:
1 | public class RatNum { |
检查表示不变量(chechRep)
例如,上面的有理数需要满足分母大于 0 且分子分母互质,可以用如下代码检查
1 | // Check that the rep invariant is true |
- 应该在每一个创建或改变(构造器,生产器, 变值器)表示数据的操作后调用
checkRep()检查表示不变量
有益的改动(beneficent mutation)
回顾之前不可变类型的定义:对象一旦被创建,其值就不会发生改变。现在学习了抽象数据类型,可以将定义更细化一下:对象一旦被改变,其抽象值不会发生改变
也就是说,对使用者来说,其代表的值是不会变的,但是实现者可以在底层对表示域做一些改动,这些不会影响到抽象域的改动称为有益的改动(beneficent mutation)
还是举前面RatNum的例子,不过我们将不变量的限制放款:不再要求分子和分母必须是最简形式
1 | public class RatNum { |
只不过,在输出它的抽象值的时候,我们对其简化:
1 | /** |
注意到观察器toString更改了numerator和denominator,即它改变了的表示域。但是关键在于,它并没有改变映射到的抽象值,我们对分子分母进行的约分和同乘 -1 的操作并没有改变
\[ AF(numerator, denominator)=numerator/denominator \]
也可以这样想,AF 是一种多对一的函数,即一个表示值可以用多种表示值来实现,所以这种改动是无害的甚至是有益的
注释 AF, RI 并说明表示泄露
应该在抽象类型表示声明后写上对于抽象函数和表示不变量的注解,描述时要清晰明确:
- 对于 RI,仅仅宽泛的说什么区域是合法的并不够,你还应该说明是什么使得它不合法
- 对于AF,抽象函数的作用是规定合法的表示值会如何被解释到抽象域,作为一个函数,我们应该清晰的知道从一个输入到一个输入是怎么对应的。
我们还要讲为什么不会表示泄露注解出来,这种注解应该说明表示的每一部分,它们为什么不会发生表示暴露,特别是处理的表示的参数输入和返回部分
下面是一个Tweet类的例子,它将表示不变量和抽象函数以及不会表示泄露注释了出来:
1 | // Immutable type representing a tweet. |
注意到我们并没有对 timestamp 的表示不变量进行要求(除了之前说过的默认 timestamp!=null)。但是我们依然需要对timestamp 的表示暴露的安全性进行说明,因为整个类型的不变性依赖于所有的成员变量的不变性
下面是关于 RatNum的另一个例子:
1 | // Immutable type representing a rational number. |
可以看到,对于不可变类型的表示,说明不会表示泄露会简单很多
ADT 的规约
我们讲了如何对表示不变量和抽象函数做注解,现在我们就来说明一下 ADT 的规约应该写什么
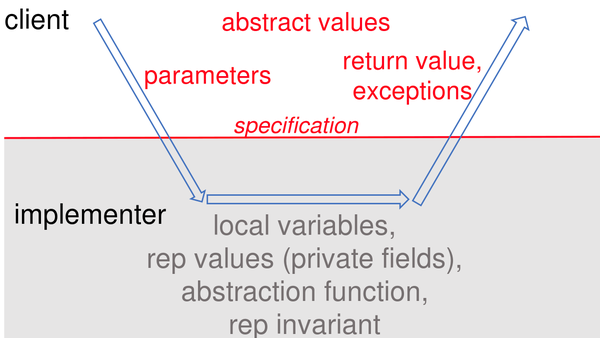
如上图
- ADT 的规约只能使用使用者可见的内容来撰写,包括参数、返回值、异常等
- 如果规约里需要提及值,只能使用抽象域中的值
- 不应谈及任何内部表示的细节,以及表示域中的任何值
- ADT 内部表示(私有属性),对外部都应该严格不可见
如何设计不变量
不变量是一种在程序中一直为真的属性,对于对象而言,就是从创建开始一直具有的属性
为了保持一个不变量,我们需要:
- 确保在对象创建的时候不变量为 true
- 确保对对象在接下来的每一个改变后不变量依然为 true
翻译成对于 ADT 的操作,就是:
- 构造器和生产器在创建对象时要确保不变量为 true
- 变值器和观察器在执行时必须保持不变性
- 在每个方法
return之前,用checkRep()检查不变量是否得以保持
表示泄露会使得情况更加复杂,如果一个表示被泄露出来,那么程序的任何地方都可能对其进行修改,我们也就没法确保不变量一直成立了。所以使用不变量完整的规则应该是:
结构归纳法,如果一个抽象数据类型的不变量满足:
- 被构造器或生产器创建
- 被变值器和观察器保持
- 没有表示暴露
那么 ADT 就是保持不变量的
用ADT不变量替换前置条件
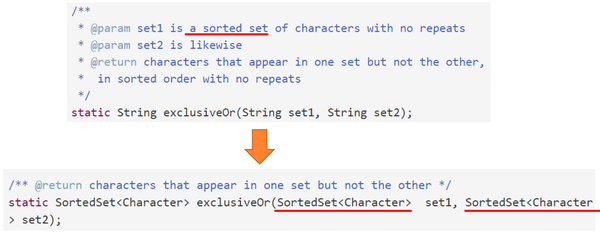
良好设计的 ADT 的一个大优点在于我们用 ADT 不变量来取代复杂的前置条件。例如,现在有一个规约:
1 | /** |
我们可以利用ADTSortedSet总是有序的不变量属性代替这种前置条件:
再举个例子,考虑下面的规约:
1 | /** |
可以设计 ADT 来取代:
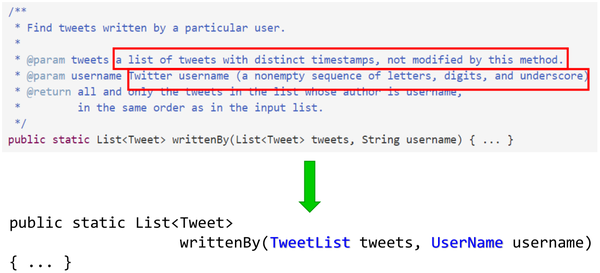
TweetList可以表示tweets有timestamps的前置条件UserName可以表示合法的username的要求
总结
本文详细阐述了抽象数据类型以及其衍生出来的抽象函数和表示不变量的概念,并举了大量的例子分析如何设计 ADT 的规约。下面还是从三方面考虑抽象数据类型的好处:
- Safe from bugs. 一个好的 ADT 会确保它的不变量总为 true,因此它们不会被使用者代码中的 bug 所影响。同时,通过显式的声明和动态检查不变量,我们可以尽早发现bug
- Easy to understand. 表示不变量和抽象函数详细表述了抽象类型中表示的意义,以及它们是如何联系到抽象值的
- Ready for change. 抽象数据类型分离了抽象域和表示域,这使得实现者可以改动具体实现而不影响使用者的代码
本文使用 Zhihu On VSCode 创作并发布